

Do Neural Networks See the World Like Us?
Backprop, brains, and visual illusions


Hello Curious Humans!
Before we get started — a quick shout-out to
from Educating AI for suggesting this topic. If you haven’t yet discovered Nick’s Newsletter — I guess the name gives it away — Nick writes about the impact of AI on education and how educators should navigate this new landscape. Nick is great, and I highly recommend his newsletter.I also want to thank
from Mostly Harmless Ideas for his insightful comments. Alejandro writes about algorithms, computer science theory, and artificial intelligence (among other things). I also highly recommend his newsletter.This article may be cut off in your email. If so, you can find the complete article here.
Okay, let’s dive in!
Are artificial neural networks like brains?
The short answer is yes and no. Probably more no than yes.
Asking whether artificial neural networks are like brains is an interesting question, but, to me, the more interesting question is whether the differences between brains and artificial neural nets are the type of differences we should care about — are the differences the type of differences that make a difference?
The human brain does a lot of things — from regulating body temperature and processing information from our senses to reconstructing memories and generating new ideas. Comparing all of the brain’s functions to those of an artificial neural network is well beyond what I could write about in one article. Actually, it’s likely well beyond what I could write about in one lifetime. So, in this article, I want to focus on one function — learning to categorise images.
Learning to categorise images is something our brains do very well, and, it turns out, artificial neural networks are pretty good at doing it too. This is especially true since the introduction of backpropagation algorithms.
Backpropagation allows the model to learn to prioritise relevant information and de-emphasise irrelevant information. The brain does something similar — it uses feedback signals to bias a neuron’s likelihood of firing. This bias allows us to focus on important information and ignore irrelevant information.
Almost 30 years ago, David Rumelhart, Geoffery Hinton and Ronald Williams published their famous backpropagation paper. In that paper, the authors acknowledge that backpropagation is not biologically plausible, given how neurons work.
So, we might want to ask how exactly backpropagation in artificial neural networks differs from how the brain works and whether these differences are the type of differences we should care about.
So, this week in When Life Gives You AI, we’re asking three questions:
What is backpropagation, and how does it work in an artificial neural network?
Does the brain do backpropagation? (spoiler alert - it doesn’t — the brain does something different), and
Are these differences the type of differences that make a difference?
But first, a question and then some caveats…
Why do we want an artificial neural network to be biologically plausible?
It’s a good question. There are two main reasons:
1.
The brain is highly efficient and adaptive, given its energy budget (~450 Calories per day). Developing algorithms that mimic this efficiency and flexibility might lead to more energy-efficient AI systems that perform a wider range of tasks.
But as Alejandro from Mostly Harmless Ideas points out, the
…biologically plausible algorithms we know of are incredibly hard to parallelize.
This is part of something called the hardware lottery, the idea that our best algorithms are heavily dependant on what kind of hardware we happened to stumble upon, much more than they are on intrinsic properties of the algorithms themselves.
So, our current hardware fundamentally limits the world of possible biologically plausible algorithms.
2.
Despite this limitation, many researchers, including a team of neuroscientists and computer scientists at the Center for Brain, Minds + Machines at MIT, are currently working on developing more biologically plausible algorithms. Their main goal isn't necessarily to craft algorithms that use the least energy or learn quickly. Instead, they're interested in working out how the brain works. The big question they're trying to answer is — when it comes to performing a function — like categorising images — does it matter what algorithm you use? Do more biologically plausible algorithms produce outcomes that are more closely aligned with human functions? or do differences in algorithms not necessarily translate to different outcomes?
Caveats:
The backpropagation version I describe here is not the only version of the backpropagation algorithm — it is the standard method, though, so we’ll focus on it.
It’s important to remember that the brain is highly interconnected. Separating specific functions and studying those functions in isolation can pose some problems. Such compartmentalisation may oversimplify the complexity of the brain and potentially overlook how some functions influence and depend on other functions.
Throughout this article, I use the term backprop — backprop is just short for backpropagation.
If you are new to neural networks, you may enjoy my article How Did We Get Here? where I use simple analogies to explain how neural networks work.
1. What is backprop, and how does it work in an artificial neural network?
An artificial neural network (ANN) is modelled on the way the brain processes information. An ANN is layered in its structure. You’ve probably seen images similar to Figure 1 before. Images like these are graphical representations of an artificial neural network, with its input, hidden, and output layers. An ANN trained to recognise cities from images, for example, would have an input layer that takes in pixels and an output layer which is the model's prediction (e.g. New York City).
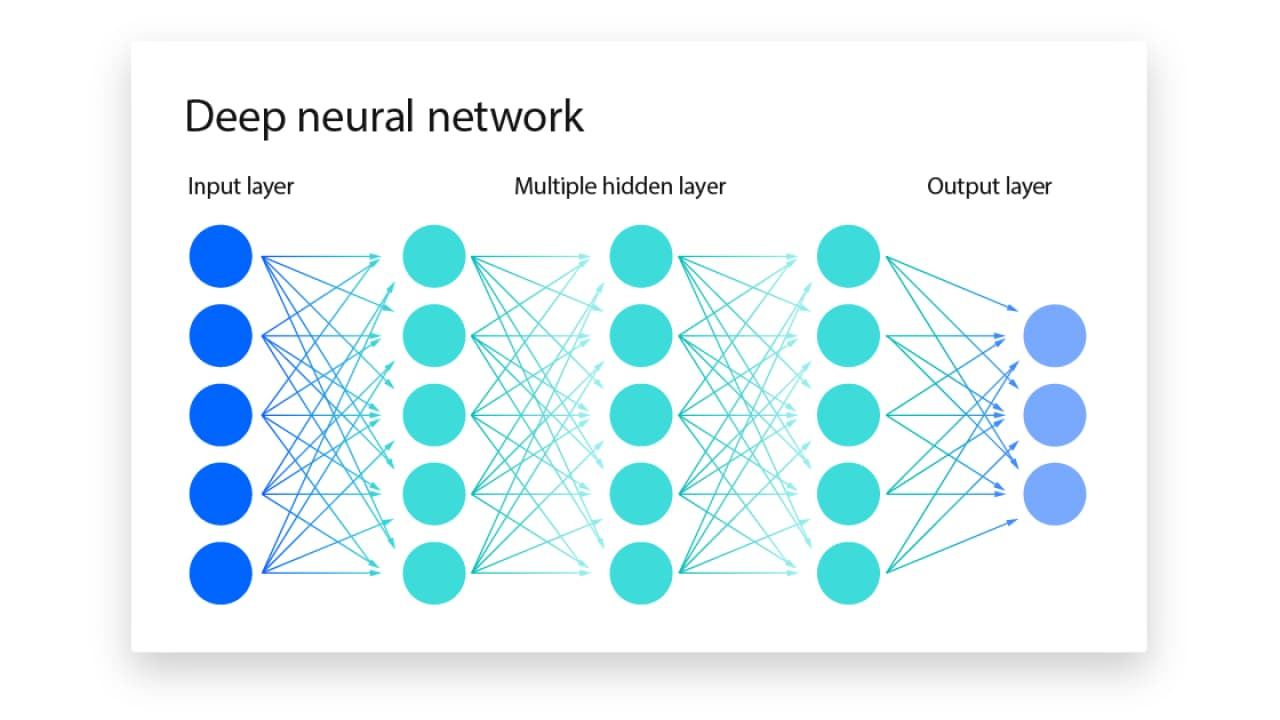
In between the input and output layers of the ANN are many — sometimes even hundreds or thousands of — hidden layers. Hidden layers in an ANN perform a crucial role by processing information at varying degrees of complexity. For example, layers situated early in the network typically handle simple aspects of images, such as lines or shading. As information progresses through the network, layers positioned further along increasingly deal with more complex components.
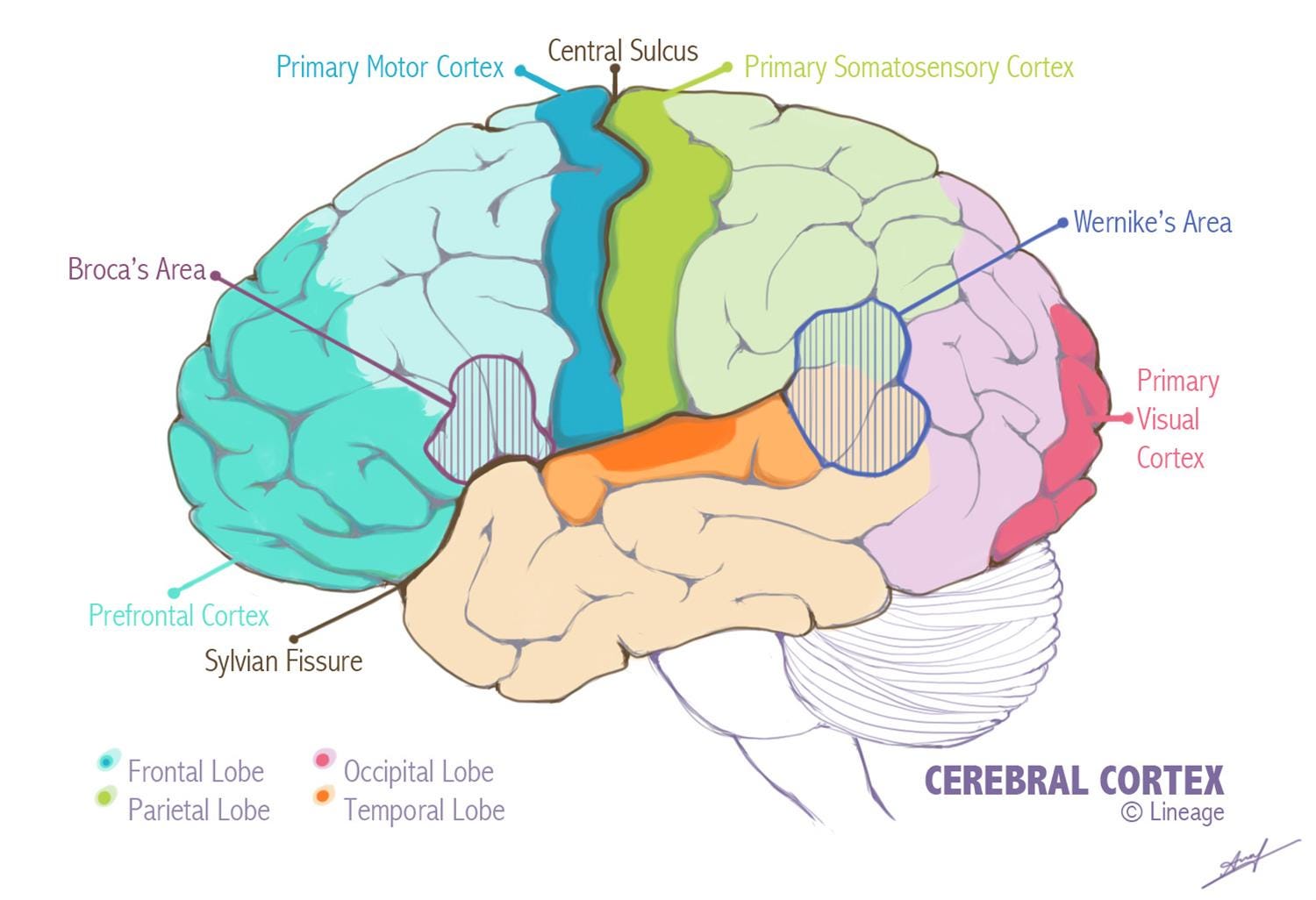
This hierarchical structure is similar to the hierarchical structure of the human visual system. In the brain, visual information progresses from the primary visual cortex (dark pink in Figure 2), where basic features like edges and orientations are processed, to the higher visual areas in the occipital lobe (light pink), which process features such as motion and colours. From there, information is passed to specialized regions in other areas of the cortex, like the temporal lobe (orange), where specific areas specialise in processing complex objects like faces, places, and houses.
In artificial neural networks, neurons are modelled as nodes (circles in Figure 1). Just like in the brain, connections between nodes can have different strengths (or weights).
In the brain’s neural network, the connection between neurons is strengthened (or weakened) by factors like the strength and timing of the electrical and chemical signals.
In artificial neural networks, the strength of the connections (weights) between nodes is learned during the training phase and is based on the training data.
When an ANN is first trained, the weights are randomly assigned. We can think of this as the model not knowing anything about the world.
There are three main steps involved in training an ANN with backprop.
Step 1: Forward Pass — Input to Output
An artificial neural network's learning process starts at the input layer, where the initial data is introduced (say, pixels from an image of New York City). From there, the data travels through several hidden layers before finally arriving at the output layer.
Along the way, each node in these layers performs a specific task. A node might have many incoming connections as well as many outgoing connections. It takes the data from preceding nodes coming in and combines this data using certain rules (these are the weighted sums, where each piece of input data is given a certain importance or weight) and then passes the result on to the next layer.
The weights are key players here—they determine how much influence each input has on the node's output. Eventually, the data reaches the output layer, which produces the final prediction (e.g., classifying the image as New York City).
It's important to note that activation functions also play a crucial role here, introducing non-linearity to the network and allowing it to learn and model complex relationships.
Step 2: Calculating the Loss
Once we have the output, we compare it against the true answer using a loss function. This function calculates the error or loss. This process essentially tells us how good our weights were. Initially, with random weights, we would expect our model to be very wrong — the error would be large.
Step 3: Backward Pass
The backward pass starts from the output layer and moves backward towards the input layer, adjusting weights based on their contribution to the loss.
We do this by calculating what’s called the gradient of the loss function. Because it is a gradient, changes in the value of the weights will either increase or decrease the loss. If we take a look at Figure 3, we see the value of the weight is plotted on the x-axis and loss is plotted on the y-axis. If we move the starting point left on the x-axis — decreasing the weight — the loss will increase. But if we move the value of the weight a little to the right — increasing the weight a little bit — we decrease the loss. And if we increase the weight a lot we start increasing the loss again.
So, in some ways, the gradient is a bit like a compass — it tells us which way to go. We don’t make random changes; instead, we nudge a weight up or down in the direction that reduces the error (loss). A separate gradient is calculated for each connection in the network.

To calculate these gradients, backpropagation uses the chain rule from calculus. This trick lets us take apart the process of calculating gradients layer by layer. We start by looking at how small changes in each node's output connections affect the error, then how changes in each node's input connections affect its output, and we keep going like this, working our way backward through the network.
After we figure out the gradients, we use them to tweak the weights all at once.
Here's how it works: we nudge each weight a bit in a direction that decreases the loss. This nudge is fine-tuned by something called the learning rate—which essentially determines how big of a step we should take. The size of these steps will depend on a few things, including the strategy being used and the size of the loss — it will make bigger steps when the loss is large and smaller steps as the model gets closer to minimizing the loss.
A step is calculated for each connection in the network. These steps are the adjustment parameters — also called deltas.
Iteration
This process of forward pass, loss calculation, and backprop is repeated many times during training, with the network processing many batches of data. With each iteration, the weights are adjusted slightly to reduce the error, gradually improving the network's predictions.
An important thing to note about ANNs
During backprop, the adjustments to the weights affect the network globally. Adjustment values — the deltas — depend not only on the immediate inputs and outputs of the node to which that weight belongs but also on the deltas downstream in the network. As a result, the process of updating weights in an ANN is global.
2. Does the brain do backprop?
I want to highlight three important differences between backpropagation and the brain.
1.
Fundamental to backprop is the forward pass and then the backward pass. This happens sequentially — first, the forward pass and then the backward pass. The network is active during the feedforward sweep, but when the error goes back through the network, the network is not active. It must pause to calculate the deltas for the entire network before it can run the forward sweep again. The brain doesn’t do this. The brain is a constant flurry of activity.

2.
Biological neurons (see Figure 4) are strictly unidirectional. Signals travel from the dendrites through the neuron's body and out via the axon to the next neuron; there is no backward flow of information in the same neuron. Synaptic strengths can change in biological neurons, a process known as synaptic plasticity, but this process is not analogous to deltas in ANNs.
3.
In contrast to ANNs, the process of updating the biological neural network is local to each neuron. The adjustment is determined by the information available to a specific neuron and its immediate connections. The activity of a neuron will only affect the neurons it is directly connected to — its influence does not extend to neurons with which it has no direct connections, making its impact localised. This is fundamentally different to the global updating used during backprop in an ANN.
So, no, strictly speaking, the brain does not do backprop.
3. Are these differences the type of differences that make a difference?
Artificial and biological neural networks perform a similar function — they learn to categorise images. They do it differently, though, and the consequence of these differences is the subject of much research in the computer- and neuro-sciences. We might like to know whether an artificial neural network sees the world as we do.
You may have seen some adversarial examples where images look identical to us, but an ANN is fooled by these images. In the image below, the panda images are easily categorised as pandas for us, but the ANN classifies the image on the left as a panda with 57.7% confidence and the image on the right as a gibbon with 99.3% confidence.
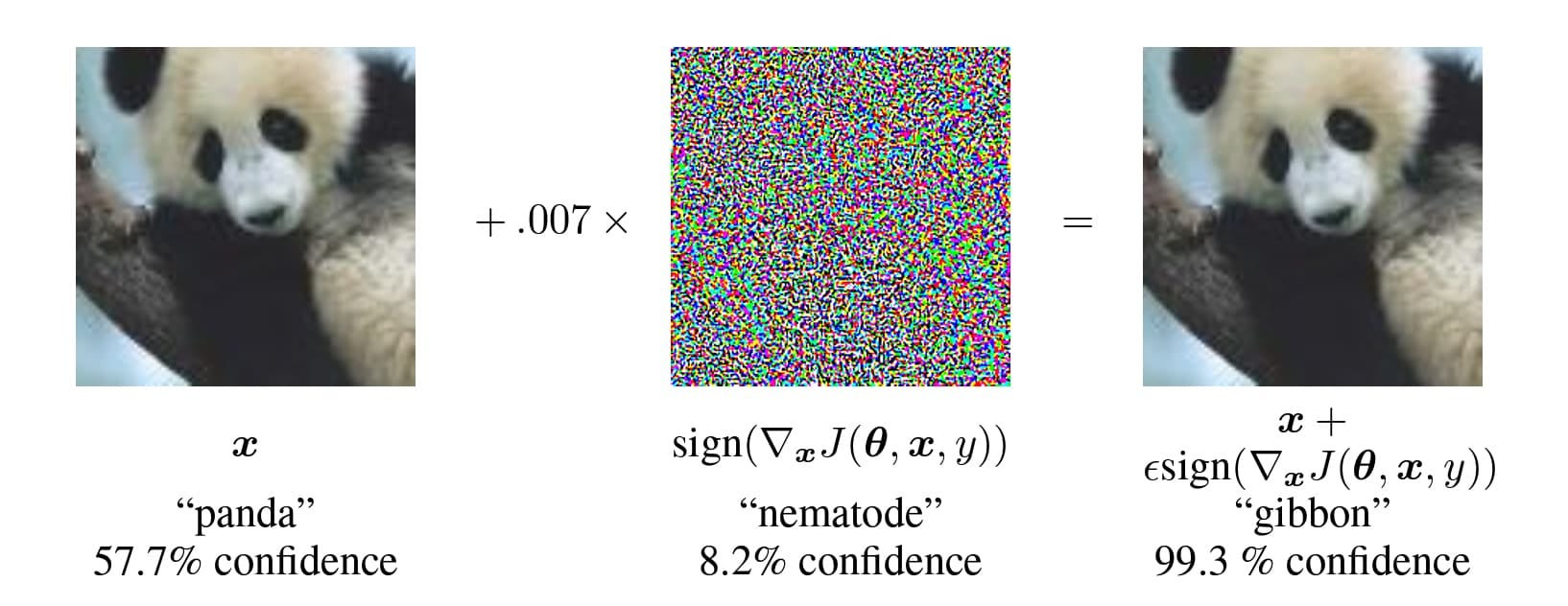
To create these images, during backprop, instead of updating the parameters according to the gradient of a panda, values are adjusted according to the gradient of a gibbon. These types of experiments tell us something about how the ANN is categorising images. ANNs don’t seem to be doing the same thing as us. But these images are specifically designed to trick the ANN. They are like visual illusions specifically designed for an ANN. ANNs are fooled by these illusions, but we are not.
Let’s flip the situation.
Humans also experience visual illusions — we don’t always see the world as it actually is. If an ANN is tricked by a visual illusion, just like a human, it could tell us something interesting about how an ANN categorises images.
Some examples of visual illusions
In Figure 5, the church is the same colour in each image but looks different due to the surrounding colours. When you look at this image, you probably have a conscious experience of a purple, pink and orange church — but, in fact, all churches are pink. This is an example of a colour visual illusion.

In Figure 6, we see the Rotating Snakes illusion. This is not a GIF. When you look at this image, you have a conscious experience of a moving image, but, in fact, this is a static image. This is an example of a motion visual illusion.

Since 2018, there have been an increasing number of studies testing whether ANNs are tricked by visual illusions — and, perhaps surprisingly to some, many of these studies show that they are. That is, the ANN shows errors similar to those of a human — it shows signs that it doesn’t see the world as it actually is. Indeed, there are studies that show that ANNs fall for both the church-type colour illusion and the Rotating Snakes illusion.
We might think that an artificial neural network sees the illusion, just like humans do.
But let’s not jump to any conclusions just yet. The devil is always in the details.
The Rotating Snakes illusion
Let’s take a closer look at the Rotating Snakes illusion to better understand what might be happening here.
The model used in the Rotating Snakes illusion study was trained to predict the next frame in natural video footage. So it was trained on a bunch of sequential video frames, and it learned to predict which frame was next in the sequence.
There are a few things to note about the Rotating Snakes illusion.
First, the motion stops if you stare at just one part of the image. If you move your eyes around, the motion starts again. This tells us that the illusion may have something to do with how our eyes work. When we look at things normally, we constantly move our eyes — these are called saccades. Saccades are rapid, jerky movements of the eyes that abruptly change the point of focus. You might not notice that your eyes are constantly moving, but this constant movement is important for human vision.
Given this, we might be surprised the ANN was tricked by the illusion — given that ANNs don’t have eyes, so they don’t make eye movements.
But there’s something else we should note about the illusion.
Each snake always rotates in the same direction. You’ll notice that for some snakes, the pattern of colours from left to right is black, blue, white, and then yellow. These snakes seem to rotate clockwise. For other snakes, the pattern from left to right is yellow, white, blue, and then black. And these snakes seem to rotate anti-clockwise.
Remember, the model was trained on natural video footage. It is possible that during training, the model has picked up on patterns or differences in colour contrast at edges, which helps it anticipate what comes next in a video sequence.
For instance, when blue and white are next to each other in a video frame, it might generally suggest that in the following video frame, the image is more likely to move towards the white area than the blue area. So, the model could perform this task without actually experiencing the illusion of motion.
But, of course, this is what we might be doing too! We might see the Rotating Snakes illusion because we’ve picked up on patterns or differences in colour contrast at edges, which causes a prediction of motion in a particular direction.
Out of interest, this model in this study was not trained using the traditional backpropagation algorithm. Instead, the model used was a more biologically plausible algorithm designed to mirror the predictive coding theory of the brain, which is currently one of the more popular theories of how the brain works.
It might be tempting to think these findings are evidence of the importance of using biologically plausible algorithms. But we can’t make that claim.
We have no evidence that other algorithms don’t produce the same results. Plus, a recent paper shows that the model does not always show signs of being tricked by the illusion. For example, the model failed to predict the illusory motion for a greyscale version of the illusion.
More biologically plausible models are still very much in the experimental phase. However, the growing buzz around such algorithms is undeniable, evidenced by a surge of research and publications on the topic over the past year. So we can’t say much except — watch this space.
But we can muse a little.
Most of the work looking at whether ANNs can be tricked by visual illusions has focused on what is called low-level visual illusions. These illusions typically exploit the basic sensory mechanisms of vision, such as light, edges, colour, and movement (features primarily processed in the visual cortex). They don't require much interpretation or understanding of the context of the image.
I would be fascinated to see if an ANN could be tricked by higher-level visual illusions. Higher-level visual illusions involve more complex processes that integrate multiple sources of information and often engage higher cognitive functions like memory, inference, and judgment. I’d be fascinated to see if an ANN could be trained to categorise illusory shapes, for example, the triangles in the Kanizsa Illusion (see Figure 6).

The Kanizsa illusion is less about the low-level sensory input (like orientation, colour, and motion) and more about our higher-level interpretation of that input. In Figure 6, we see a triangle on the left, even though no triangle actually exists. You have a conscious experience of a triangle — but there is no triangle. The illusion depends on the arrangement of the Pacman-like figures. The triangle disappears if we rotate the Pacman-like figures (right in Figure 6).
Would an artificial neural network trained to identify shapes recognize the image on the left as a triangle but not classify the image on the right as one?
We could set up an experiment where models are trained to categorise real, not illusory, images of shapes — say triangles, squares, hexagons etc. Different types of models could be trained, from backpropagation to other more biologically plausible algorithms. Then, we test these models on illusions like the Kanizsa illusion — which physically does not contain any of the shapes the models were trained on. The interesting question would be, which models are tricked by this higher-level illusion?
I’d be fascinated if any model was tricked by a higher-level illusion, but I would be particularly interested in how each model performed. Would more biologically plausible models be more susceptible to being tricked by the illusion than less biologically plausible models? or is the difference in model structure a difference that makes no difference?
What this Might mean for Consciousness
The research on ANNs being tricked by visual illusions raises some interesting questions for consciousness. While it's tempting to anthropomorphize ANNs as seeing these illusions, there might be simpler reasons behind their responses.
The idea that an artificial neural network might be tricked by higher-level visual illusions like the Kanizsa Illusion is fascinating. If an ANN, trained to recognize shapes, categorises those shapes in the Kanizsa Illusion, it would likely have many asking, what does it mean for our understanding of consciousness?
The Sum Up
Do ANNs categorise images like us? Regarding early processes — like processing orientations, colours, motions, etc. — I think ANNs and humans are strikingly similar. But when we get to the later stages — where the human brain and ANNs start to process more complex things like categories of objects — it seems that ANNs trained on backprop operate quite differently from the way humans do, and these differences make a difference. Whether these differences are intrinsic to the algorithms or other factors is the subject of ongoing research.
An excellent article that raises some critical questions about perception and intelligence.
It certainly is way easier to just equate AI to human brains but the more we dig into human brains and realize how little we actually know the more we have to accept 'it's complicated.' Great essay that covers a lot of detail.