

How Did We Get Here? The 3 Key Breakthroughs That Have Shaped the Development of AI


#01 - In this issue:
❃ How we got Deep Neural Networks and why they are so important
❃ How advances in Data Storage have been an important catalyst
❃ The role of GPUs in AI advancement
Hello curious humans!
I recently introduced my parents to ChatGPT.
“We’re in a new era”, I proclaimed. “Artificial Intelligence is here to transform our lives!” To which they responded with obligatory oohs and aahs.
But then, amid the mild excitement, my Mum dropped a simple question that was surprisingly difficult to answer.
How did this happen?
ChatGPT seems to be the poster child for a major paradigm shift. Indeed, many have described this new AI era as the Fourth Industrial Revolution.
Such monumental transitions in history often start with just a handful of pivotal innovations and breakthroughs.
If we think about the past 3 Industrial Revolutions, we notice that there were a few key inventions that sparked big changes.
The 1st Industrial Revolution was spurred on by the steam engine, machines that replaced hand tools, and the factory system.
During the 2nd Industrial Revolution, it was the telephone, electrification, and the typewriter.
In the recent Digital Revolution (or the 3rd Industrial Revolution) it was (arguably) mandatory education, the Internet, and innovation.
So, I wondered…
What are the three big catalysts of the AI Revolution?
In this first issue of When Life Gives You AI, I’ll take a closer look at what I think are the 3 most influential factors that have sparked the AI Revolution:
1. Deep Neural Networks,
2. Data Storage, and
3. GPUs.
But first, a few caveats.
There are almost certainly more than 3 factors that have converged to drive the AI Revolution. For example, I don’t think we would have seen this new wave without a culture of democratisation and the lack of regulation surrounding AI applications. But I’m going to keep this article about technological influences rather than cultural and political ones.
This article is loosely based on the conversation I had with my parents. Just as I did in the actual conversation, I will use examples and analogies to try to explain some complex concepts. Like all good analogies (and bad ones), they never fit exactly right. Analogies often overlook important details. But I will use them anyhow because they can be a great place to start when trying to grasp complex or fundamental concepts.
Right, with those caveats in place, let’s dive deep into Deep Neural Networks.
What the heck is a Deep Neural Network and why are they so important to artificial intelligence?
Before we jump into that juicy question, let’s step back a bit and talk about traditional computer programming.
There are two things to note about traditional computer programming:
Traditional computer code follows a sequential process. Tasks are completed one at a time, in a specific order. This is similar to following a step-by-step recipe when cooking. For example, mix the wet ingredients before adding them to the dry ingredients. It's a step-by-step procedure where each step depends on the completion of the previous one.
It's deterministic – meaning if you input the same data, you'll get the same output every time. It doesn't learn or adapt based on previous runs.
Neural networks, on the other hand, are great at generalizing. This means they can learn patterns from data and apply this learning to new, unseen data. It’s like learning the concept of cooking rather than just memorizing a single recipe.
Neural networks, particularly deep neural networks, don’t strictly adhere to a linear, step-by-step path. They process information in a more interconnected way, a bit like how our brains work.
The Real Neural Network
In fact, neural networks in computers (also called artificial neural networks) are inspired by the real neural networks in the brain. Our understanding of neuroscience has had a huge influence on the field of artificial intelligence.
Brain neurons (see Figure 1) receive input signals through their dendrites, process these signals in the cell body (also known as the soma), and then transmit output signals to other neurons through the axon. This process is fundamental to how neurons in the brain communicate and forms the basis of how neurons in the computer (called nodes) work in artificial neural networks.

In the human brain, the points where neurons connect and communicate are called synapses. This is where the electrical or chemical signals are transmitted to other neurons.
In artificial neural networks, the structure is simplified and abstracted. Neurons are modelled as nodes, and the synapses are represented as connections between these nodes. Just like in the brain, connections between nodes can have different strengths (or weights).
In the brain’s neural network, the connection between neurons is strengthened (or weakened) by factors like the strength and timing of the electrical and chemical signals.
In artificial neural networks, the strength of the connections between nodes (weights) is learned during the training phase and is based on the training data.
The First Artificial Neural Networks
Perceptions are often considered to be one of the earliest examples of artificial neural networks. They were designed to mimic a neuron, capturing the concepts of inputs, weights, processing, and outputs.
Perceptrons were first introduced by Frank Rosenblatt in 1957. Unlike artificial neural networks of today, they were implemented in a physical device.
The initial and most famous application was for image recognition, specifically for distinguishing simple shapes and patterns like squares, circles and triangles.
The machine had a 20x20 grid of 400 photocells (light detectors) that could detect light patterns. These photocells served as the inputs for the perceptron.
Like a pixel in modern digital images, each photocell only captured a small, localized part of the entire image.
We can think of each photocell (or pixel) as a piece of a jigsaw puzzle. Each piece doesn't give you the whole picture; it only shows a tiny part of it (see Figure 2). Similarly, each photocell in a perceptron captures just a fragment of the entire image - maybe a corner of a square or a curve of a circle.

Imagine a simple game where you have a bag full of jigsaw pieces. All the pieces in the bag join together to form a picture of a square, a circle, or a triangle. These puzzle images are simple with just two colours, a black background and a white shape. But you don’t know which shape is on the puzzle in your bag. Your task is to pull puzzle pieces out of the bag and to decide the importance of this puzzle piece in deciding whether the image is a square, a circle, or a triangle.
In the bag some jigsaw pieces provide crucial information that helps in defining the shape. Black and white pieces (like the middle puzzle piece in Figure 4 below) are more helpful in identifying the shape than pieces that contain only one colour (the puzzle pieces on the left and right in Figure 3).

Imagine a not-so-smart perceptron, that doesn’t know that some pieces contain more information than other pieces. At first, it randomly assigns the importance (weights) to the different pieces (input layer). Summing the weighted inputs, the perceptron takes a guess of the shape (output layer). Feedback is given in the form of an error score. Adjusting its weights (a process that is typically done through an algorithm like gradient descent), the perceptron tries again. Slowly over many, many trials, it learns which features provide the most information and, therefore, should receive the highest weights.
The following image and equation are for those who find the math helpful. If you are not one of those people, feel free to skip over it.
Figure 4 is a visual representation of a single-layer artificial neural network with four nodes in the input layer and one output value. Each connection between the nodes is assigned a weight.

y represents the output of the neural network.
∑ denotes the summation.
wi represents the weight corresponding to the i-th input.
xi is the i-th input.
b is the bias term, which is added after the weighted sum.
One Layer Learning
In the classic perceptron model developed by Frank Rosenblatt, there is just one layer of the network where the weights can change. It's designed to perform binary classifications and can adjust its weights based on the inputs it receives. Inputs are multiplied by weights and summed up to produce an output.
Multiple layered Neural Networks
Early AI systems, like the perceptron, set some lofty expectations for neural networks. Unfortunately, these AI systems struggled with fundamental issues like a lack of computational power. And the 70s became a period of reduced funding and interest in artificial intelligence research — or the first AI winter.
Hopes were raised in the 1980s, when David Rumelhart, Geoffrey Hinton, and Ronald Williams described a new algorithm (backpropagation) that made it feasible to train a multi-layer neural network. This discovery led to a resurgence of interest in neural networks.
But the interest in AI didn’t last long. Although multi-layered neural networks were an important breakthrough, which allowed neural networks to learn and adapt, they faced significant limitations. These networks struggled to effectively train beyond a few layers deep.
Why Neural Networks are better when Multi-layered
To understand the importance of a multi-layered neural network we need to go back to our puzzle example.
Imagine, after you pick up a puzzle piece (input layer), but before you decide which shape it belongs to (output layer), you implement a second step where you group the pieces with others that have similar features. For example, you make three piles, all the white pieces go into the first pile, all the black pieces go into the second pile, and all the black and white pieces go into the third pile.
This grouping is like a hidden layer in a neural network (Figure 5). It's a stage of processing where you organize and interpret the information before making a final decision. In our puzzle example, the hidden layer has three nodes based on features — all black pieces, all white pieces, and black and white pieces.
The importance of the hidden layer lies in its ability to learn which features of the puzzle are most informative. As the network trains, it adjusts the weights (the significance it assigns to each feature), learning, for instance, that the mixed-colour pieces provide more valuable information than the single-colour pieces.
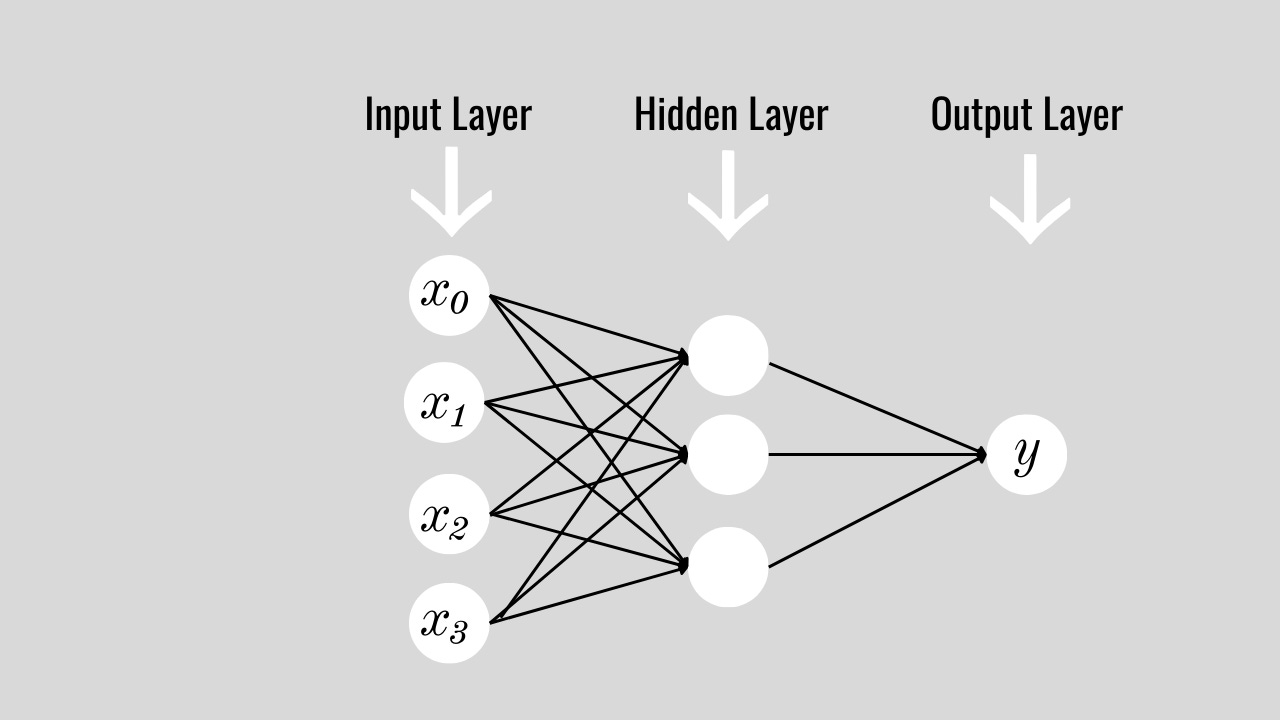
Adding an extra step in the puzzle-solving game makes the neural network more effective. We could even add a second hidden layer, so each hidden layer becomes a more refined stage of categorization or interpretation. For instance, after sorting the pieces into black, white, and black-and-white piles (the first hidden layer), a second hidden layer could further analyze pieces (perhaps the angle of the line on black and white pieces).
This layered approach allows the network to understand more complex relationships and patterns within the data, leading to a more accurate identification of the puzzle's shape. Just as you might first sort by colour and then angle, multi-layered neural networks can capture a deeper, more nuanced understanding of the data, significantly improving their problem-solving capability compared to a network with only a single layer of processing.
The Second AI Winter
Imagine trying to solve a highly complex puzzle with many layers of interpretation, not just colour and angle but also shade variations, piece shape, and more. Each layer adds complexity (more nodes and more connections between the nodes), and without sophisticated methods to guide the sorting process, it becomes increasingly difficult to discern which features are truly relevant to solving the puzzle and which are just noise.
In early attempts at multi-layered neural networks, this manifested as issues like vanishing gradients, where the adjustments (gradients) used to update network weights became increasingly smaller in deeper layers, making learning ineffective. Additionally, computational limitations and a lack of large, diverse datasets constrained the potential of these early multi-layered networks, contributing to the second AI winter.
1. Deep Neural Networks
It wasn’t until the early 2010s that we saw our first big catalyst in the AI Revolution — true multi-layer neural networks (also called deep neural networks). The breakthrough, led by Geoffrey Hinton, marked a significant advancement in the field of artificial intelligence, bringing us closer to a form of processing more akin to the human brain.
1.1 How Deep Neural Networks Are Like Brains
1.1.1 Layered Processing
The human brain processes information through a complex hierarchy of neurons and synapses. Similarly, deep neural networks process data through multiple layers of nodes (artificial neurons). Each layer in these networks can be seen as a level of abstraction or interpretation, much like how different regions of the brain specialize in processing different types of information.
In the brain, information is processed, and patterns are recognized in a hierarchical manner — basic features (like orientation and colour) are processed first, followed by more complex patterns built upon these features (like objects and faces). Similarly, in deep artificial neural networks, lower layers might detect simple patterns (like edges in an image), while deeper layers can identify more complex features (like shapes or objects). This hierarchical processing is key to the brain's ability to understand complex stimuli, and deep neural networks mimic this to improve their learning and predictive abilities.
1.1.2 Learning and Adaptation
The brain's ability to learn and adapt — known as neuroplasticity — involves strengthening or weakening synaptic connections based on experiences. Deep neural networks similarly adjust the weights (the importance) of connections between nodes during the learning process, allowing them to improve at tasks through experience (training data).
1.1.3. Handling Complexity
The brain efficiently manages and interprets the vast amounts of data it receives from the senses. Deep neural networks, with their many layers, can handle and interpret complex, high-dimensional data more effectively than their shallower counterparts. This capability is essential for tasks like image and speech recognition, where the data is intricate and multi-layered.
1.2 The Cost of Complexity
However, this complexity comes at a cost: the brain consumes about 20% of the body's energy despite making up only about 2% of its mass. Similarly, in the world of artificial intelligence, as neural networks grew deeper and more complex, mirroring the layered processing of the brain, they required exponentially more computational power and data.
Developing advanced deep neural networks required a leap in resource technology — specifically innovation in data storage and harnessing the processing power of GPUs.
This leads us to the second catalyst in the AI Revolution.
2. Data Storage
In the AI early years, data storage was limited, both in capacity and speed. Consequently, the size and complexity of neural networks were significantly constrained.
2.1 Storage Capacity
The development of deep neural networks would not have been possible without the advent of cloud storage and advancements in solid-state drive (SSD) technology. These innovations enabled the storage of petabytes of data required for training and operating complex deep neural networks.
A deep neural network requires a large and diverse dataset to learn effectively. This is because:
The more varied the data, the better the network can learn the multitude of patterns and nuances present in real-world scenarios.
The more examples it has, the better it understands and generalizes from the patterns it encounters.
A deep neural network, with its many layers, needs enough data to ensure each layer can learn effectively from the information passed on by the previous layers.
2.2 Speed
During training, deep neural networks with multiple layers perform an immense number of calculations, often reaching into the billions or even trillions. The efficiency of this computationally intensive training process is limited primarily by two factors: the speed of data access and the speed of data processing.
Advances in data storage technology have significantly alleviated the first constraint. Modern data storage solutions offer faster data retrieval speeds, reducing the time neural networks spend waiting for data.
The second constraint — the speed of data processing — has been effectively addressed by the advent of GPUs.
3. GPUs

3.1 What is a GPU?
A GPU, or Graphics Processing Unit, is a physical component in your computer, similar in appearance to a small rectangular card. It typically slots into the motherboard (the large circuit board inside your computer). If you've ever seen someone playing a high-end video game on their computer, the smooth graphics are likely thanks to the GPU. You can think of a GPU as a mini-computer within your computer, dedicated to making graphics look good and run smoothly. But, it turns out that GPUs are also good at other tasks that require a lot of processing, like the handling of large amounts of calculations performed in training AI.
3.2 Who is Nvidia?
Nvidia is a key technology company that makes GPUs used in gaming and professional applications, like AI. They are also responsible for a key piece of software called CUDA. CUDA is what allows GPUs to do more than just make games look good. This software allows programmers to write and execute code that takes advantage of a key aspect of GPUs — its parallel processing capabilities.
3.3 Why is parallel processing so important to AI?
AI, particularly in fields like deep learning, demands the handling of huge datasets and the execution of countless calculations. Picture the daunting task of sequentially performing billions of calculations, akin to methodically following a one-billion-step recipe step-by-step. Parallel processing revolutionised AI by allowing concurrent calculations on numerous data points. This drastically accelerates the training process.
Some AI applications, like autonomous vehicles or real-time language translation, require immediate processing of information. Parallel processing allows these tasks to be performed in real-time, as it can handle multiple inputs and computations simultaneously.
The Sum Up
So there you have it — the three key breakthroughs that have propelled us into the AI Revolution — deep neural networks, advances in data storage, and GPUs.
I'm eager to hear your thoughts. Do you agree? Are these the pivotal advancements you would pick? Are we really in the 4th Industrial Revolution? Or are we destined for another AI winter?
In the next issue…
On AI and Consciousness
Consciousness is a complex and often debated concept in both philosophy and science. As AI systems become more advanced, the question of AI consciousness arises.
Where do we even start with these sorts of questions?
In the next issue of When Life Gives You AI, I’ll outline three of the big questions that we need to address if we have any hope of understanding whether AI could be conscious.
Find it in your inbox on Tuesday, January 23, 2024.
Wow, just discovered this substack. Excellent, clear descriptions and explanations of the complex fundamentals underlying machine learning. The author grasps and communicates the arcane scientific principles of information theory and physics so well. What a great resource for aspiring data scientists!
Well explained post on what enabled AI. Wonderful how concepts invented long back gain a huge leap when the right hardware for them arrives.